Сбор данных из социальной сети Тинькофф Пульс (python, sqlite3)

Вступление
В этой статье я хочу поделиться с вами опытом о том, как просто можно забрать (спарсить) данные из социальной сети Тинькофф “Пульс” c помощью python и sqlite3
Начнем:
Для начала следует понимать, что данные (т.к. они идентичны для всех устройств и хранятся в одном месте), как на сайт, так и в приложение попадают через единую точку REST API - от нас требуется только найти ее через инструменты разработчка в браузере. Вводим в строку поиска instrument и видим несколько запросов, с характерой частью api в строке запроса.
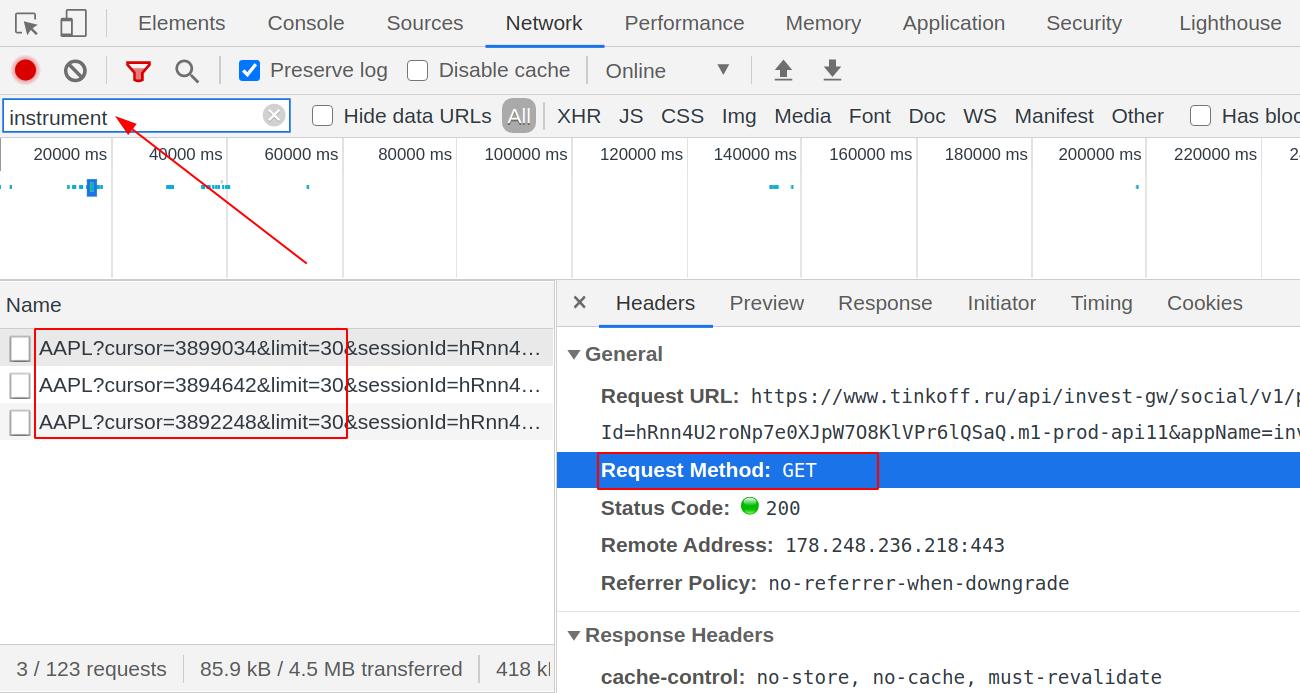
Давайте скопируем адрес одной из ссылок:
https://www.tinkoff.ru/api/invest-gw/social/v1/post/instrument/AAPL?cursor=3899034&limit=30, как мы видим - строка запроса состоит из нескольких частей:
- Основная (доменное имя)
https://www.tinkoff.ru - Машрутизация
/api/invest-gw/social/v1/post/instrument/AAPL?cursor=3899034&limit=30
В ней нас интересуют части AAPL - название тикера, ?cursor=3899034 - курсор для “обновления” новых постов в момент, когда мы прокручиваем ленту вниз и &limit=30 - кол-во постов, которые будут получены в рамках 1 запроса.
Можно попробовать сделать запрос к API прямо из браузера: Запрос! - работает, двигаемся дальше.
Переходим к коду
Для комфортной работы нам потребуется 2 допольнительных библиотеки: pytz и requests.
Предварительно создадим отдельное виртуальное окружение env.
python -m venv env ; \
source env/bin/activate
Установка:
pip install requests && pip install pytz
Базовые импорты:
import requests
import sqlite3
from time import sleep
from datetime import datetime
from pytz import timezone
Для того, чтобы сервер не заметил того, что мы не являемся человеком и запросы отправляются скриптом - добавим несколько HTTP заголовков в запрос.
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'accept': '*/*',
'content-type': 'application/x-www-form-urlencoded',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7'
}
Первая функция на запрос и обработку ответа сервера
Заранее подготовим шаблон строки запроса, в который будут подставляться значения
(на месте {})
'https://www.tinkoff.ru/api/invest-gw/social/v1/post/instrument/{}?limit=50&appName=invest&platform=web&cursor={}'
def get_data_from_api(url: str, ticker: str, cursor_number: str) -> None:
link = url.format(ticker, cursor_number)
session = requests.Session()
data = session.get(link, headers=headers, stream=True)
raw_data = data.json().get('payload').get('items')
for i in raw_data:
my_data = {
'ticker': ticker,
'id': i.get('id')[:7],
'inserted': convert_inserted(i.get('inserted')),
'instruments': ', '.join(get_instruments(i.get('instruments'))),
'likesCount': i.get('likesCount'),
'nickname': i.get('nickname'),
'commentsCount': i.get('commentsCount'),
'parse_date': datetime.today().strftime('%Y-%m-%d %H:%M:%S')
}
print(my_data)
insert('dt_pulse', my_data)
Как видно из кода фукнции - 3м аргументом принимается некий cursor_number, это как раз и есть номер для фиксации нового среза данных. Для его корректного определения напишем отдельную функцию.
def get_cursor(url: str, ticker: str, cursor_number: str) -> str:
link = url.format(ticker, cursor_number)
session = requests.Session()
data = session.get(link, headers=headers, stream=True)
cursor_number = data.json().get('payload').get('nextCursor')
return cursor_number
Определение курсора - есть, функция для получения данных с одного запроса - тоже есть, осталось их объединить в одно целое. Как пример - будем забирать 100 постов с тикера AAPL.
def get_data_from_ticker(ticker: str) -> None:
max_cursor = '99999999999'
for _ in range(1, 3):
get_data_from_api(link, ticker, max_cursor)
sleep(0.5)
max_cursor = get_cursor(link, ticker, max_cursor)
sleep(0.8)
# RUN
get_data_from_ticker('AAPL')
Отлично! Данные по отдельным постам формируются в отдельный dict, давайте перенесем их в базу данных. Как пример - будем использовать sqlite3, которая есть “из коробки” на любой unix машине.
Добавим sql-файл create_table.sql с кодом на создание таблицы:
create table dt_pulse(
src_id int primary_key,
ticker varchar(10) not null,
id char(7) not null,
inserted timestamp not null,
instruments varchar(1000) not null,
likesCount int not null,
nickname varchar(55) not null,
commentsCount int not null,
parse_date timestamp not null
);
Инициализация БД и запуск нашего файла.
conn = sqlite3.connect('pulse-parser.db')
cursor = conn.cursor()
def _init_database():
with open('create_table.sql', 'r') as f:
sql = f.read()
cursor.execute(sql)
conn.commit()
Универсалья функция для вставки insert данных в нашу таблицу, которая принимает 2 аргумента:
- Название таблицы
table_name Dictс даннымиcolumn_data, из которого сформируется набор столбцов
def insert(table_name: str, column_data: dict) -> None:
columns = ', '.join(column_data.keys())
values = [tuple(column_data.values())]
placeholders = ', '.join('?' * len(column_data.keys()))
cursor.executemany(
f'insert into {table_name}({columns}) values({placeholders})', values
)
conn.commit()
Просмотр полученных данных
Откроем наш файл с бд pulse_lesson.db с помощью команды
sqlite3 pulse_lesson.db
Внутри консоли выполним:
.mode box- для вывода данных в табличном виде.tables- для просмотра списка таблиц
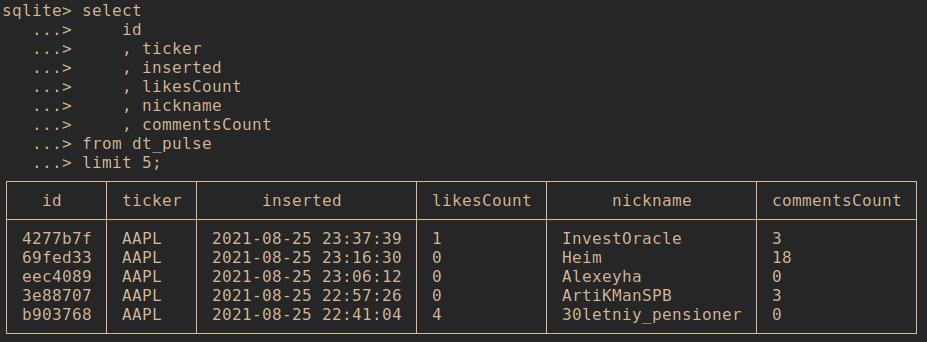
select
id
, ticker
, inserted
, likesCount
, nickname
, commentsCount
from dt_pulse
limit 5;
Результат:
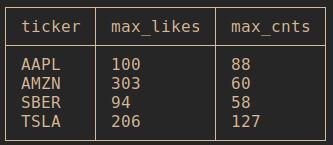
Добавим немного группировки
select
ticker
, max(likesCount) as max_likes
, max(commentsCount) as max_cnts
from dt_pulse
group by ticker;
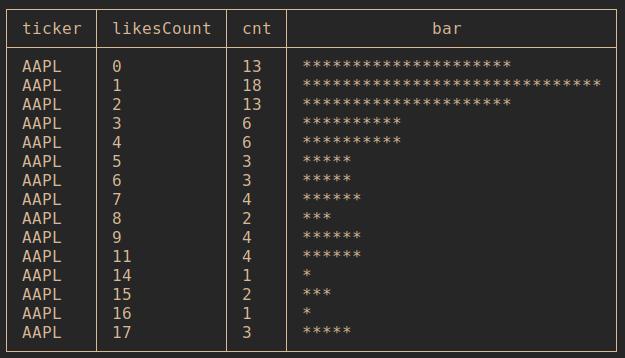
Распределение по кол-ву лайков AAPL
with t1 as
(
select
likesCount
, count(*) as cnt
from dt_pulse where ticker = 'AAPL' group by likesCount
)
select
'AAPL' as ticker
, likesCount
, cnt
, printf('%.' || (cnt*30 / (select max(cnt) from t1)) || 'c', '*') as bar
from t1 order by likesCount asc limit 15;
Результат:
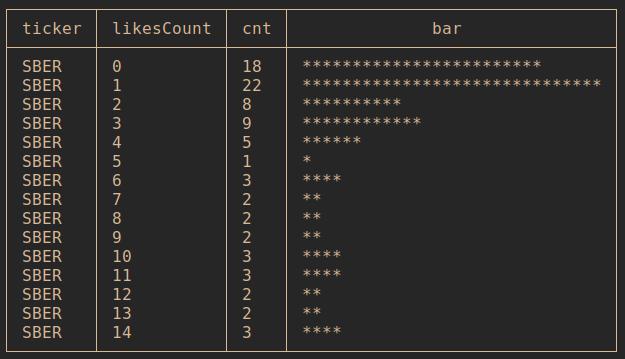
Распределение по кол-ву лайков SBER
with t1 as
(
select
likesCount
, count(*) as cnt
from dt_pulse where ticker = 'SBER' group by likesCount
)
select
'SBER' as ticker
, likesCount
, cnt
, printf('%.' || (cnt*30 / (select max(cnt) from t1)) || 'c', '*') as bar
from t1 order by likesCount asc limit 15
Результат:
Полный код (ровно 100 строк)
import requests
import sqlite3
from time import sleep
from pytz import timezone
from datetime import datetime
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'accept': '*/*',
'content-type': 'application/x-www-form-urlencoded',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7'
}
link = 'https://www.tinkoff.ru/api/invest-gw/social/v1/post/instrument/{}?limit=50&appName=invest&platform=web&cursor={}'
conn = sqlite3.connect('pulse_lesson.db')
cursor = conn.cursor()
def _init_database():
with open('create_table.sql', 'r') as f:
sql = f.read()
cursor.execute(sql)
conn.commit()
def insert(table_name: str, column_data: dict) -> None:
columns = ', '.join(column_data.keys())
values = [tuple(column_data.values())]
placeholders = ', '.join('?' * len(column_data.keys()))
cursor.executemany(
f'insert into {table_name}({columns}) values({placeholders})', values
)
conn.commit()
def get_instruments(lst: list):
data = []
for item in lst:
line = f"{item.get('briefName')} !! {item.get('ticker')} !! {item.get('price')} !! {item.get('lastPrice')}"
data.append(line)
return data
def convert_inserted(line):
utc_time = datetime.strptime(line, '%Y-%m-%dT%H:%M:%S.%f%z')\
.replace(tzinfo=timezone('utc')).strftime('%Y-%m-%d %H:%M:%S')
return utc_time
def get_cursor(url: str, ticker: str, cursor_number: str) -> str:
link = url.format(ticker, cursor_number)
session = requests.Session()
data = session.get(link, headers=headers, stream=True)
cursor_number = data.json().get('payload').get('nextCursor')
return cursor_number
def get_data_from_api(url: str, ticker: str, cursor_number: str) -> None:
link = url.format(ticker, cursor_number)
session = requests.Session()
data = session.get(link, headers=headers, stream=True)
raw_data = data.json().get('payload').get('items')
for i in raw_data:
my_data = {
'ticker': ticker,
'id': i.get('id')[:7],
'inserted': convert_inserted(i.get('inserted')),
'instruments': ', '.join(get_instruments(i.get('instruments'))),
'likesCount': i.get('likesCount'),
'nickname': i.get('nickname'),
'commentsCount': i.get('commentsCount'),
'parse_date': datetime.today().strftime('%Y-%m-%d %H:%M:%S')
}
print(my_data)
insert('dt_pulse', my_data)
def get_data_from_ticker(ticker: str):
max_cursor = '99999999999'
for _ in range(1, 3):
get_data_from_api(link, ticker, max_cursor)
sleep(0.5)
max_cursor = get_cursor(link, ticker, max_cursor)
sleep(0.8)
def main():
_init_database()
get_data_from_ticker('AAPL')
get_data_from_ticker('AMZN')
get_data_from_ticker('TSLA')
get_data_from_ticker('SBER')
if __name__ == '__main__':
main()
Если вам интересны подобные рассуждения, подписывайтесь на мой канал artydev & Co.