Оптимизация управления ресурсами очереди Hadoop кластера
![]()
Введение
В данной статье я хотел бы поделиться результатами кастомного сервиса, который следит за корректной утилизацией yarn очереди на Hadoop кластере. Если рассматривать алгоритм подробнее, то логика заключается в следующем: каждый час запускается проверка, которая собирает базовую информацию по ресурсам, аллоцированным SPARK-приложениями и данные по истории запусков.
Ключевыми метриками являются:
- кол-во часов с момента запуска последней таски (запуск внутри приложения)
- кол-во часов с момента создания приложения и наличие тасок
spark-context считается подходящим для “отключения” в двух случаях:
- если пункт 1 удовлетворяет условию >= 2 часов
- если пункт 2 удовлетворяет условию > 12 часов
По результатам запуска сервис собирает статистику по нагрузке кластера в локальную sqlite3 базу, на основе этих данных можно провести анализ.
Подготовка данных
Сырая таблица состоит из столбцов:
id- sequence в таблицеapplication_id- идентификатор форматаapplication_1642165469933_316514start_time- дата создания приложения в форматеYYYY-MM-DD HH:MM:SScreate_t_ago- кол-во часов с момента создания приложенияuser- пользовательtype- тип (SPARK, HIVE)cpu- кол-во ядер CPU используемые приложениемmemory- кол-во RAM используемые приложениемt_last_run- кол-во часов с последней активной таски приложенияapp_name- название приложенияkill_reason- причина отключенияparse_dt- дата сбора информации в форматеYYYY-MM-DD HH:MM:SS
Из такого состава таблицы не совсем понятно, какие данные были собраны в рамках одного запуска, необходимые для того, чтобы понять утилизацию в определенный момент времени (в to_date(parse_dt) содержатся >= 24 порции данных, т.к. сбор просходит каждый час)
Ранжируем выборку выделив в качестве доп. ключа № запуска YYYY-MM-DD HH из YYYY-MM-DD HH:MM:SS с помощью оконной функции dense_rank().
create view v_cluster as
select
id
, app_id
, start_time
, created_t_ago
, user
, type
, cpu
, memory
, t_last_run
, app_name
, kill_reason
, parse_dt
, date(parse_dt) as dt
, dense_rank() over(order by substr(parse_dt, 1, 13) asc) as run_number
from cluster_mon
where date(parse_dt) >= date('2022-02-19');
Всего было произведено 1363 запуска сервиса.
Анализ
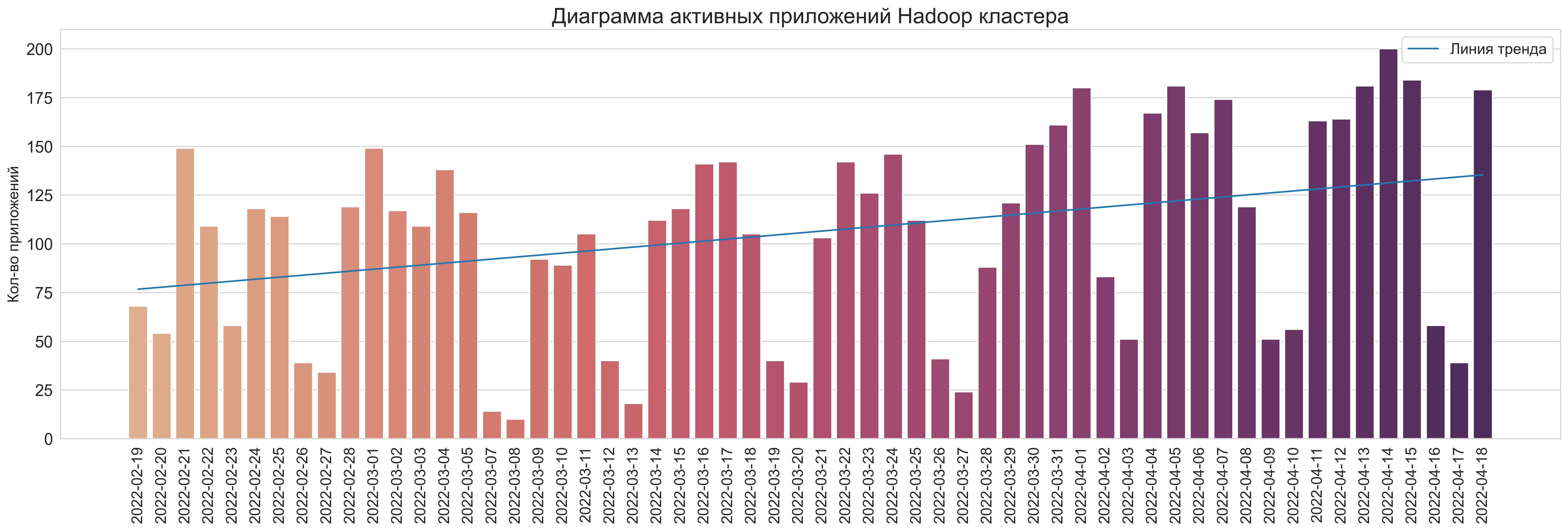
Активные приложения на временном промежутке
select
count(distinct(app_id)) as app_count, dt
from v_cluster group by dt
order by dt asc
Активные пользователи на временном промежутке
select
count(distinct(user)) as user_count, dt
from v_cluster group by dt
order by dt asc
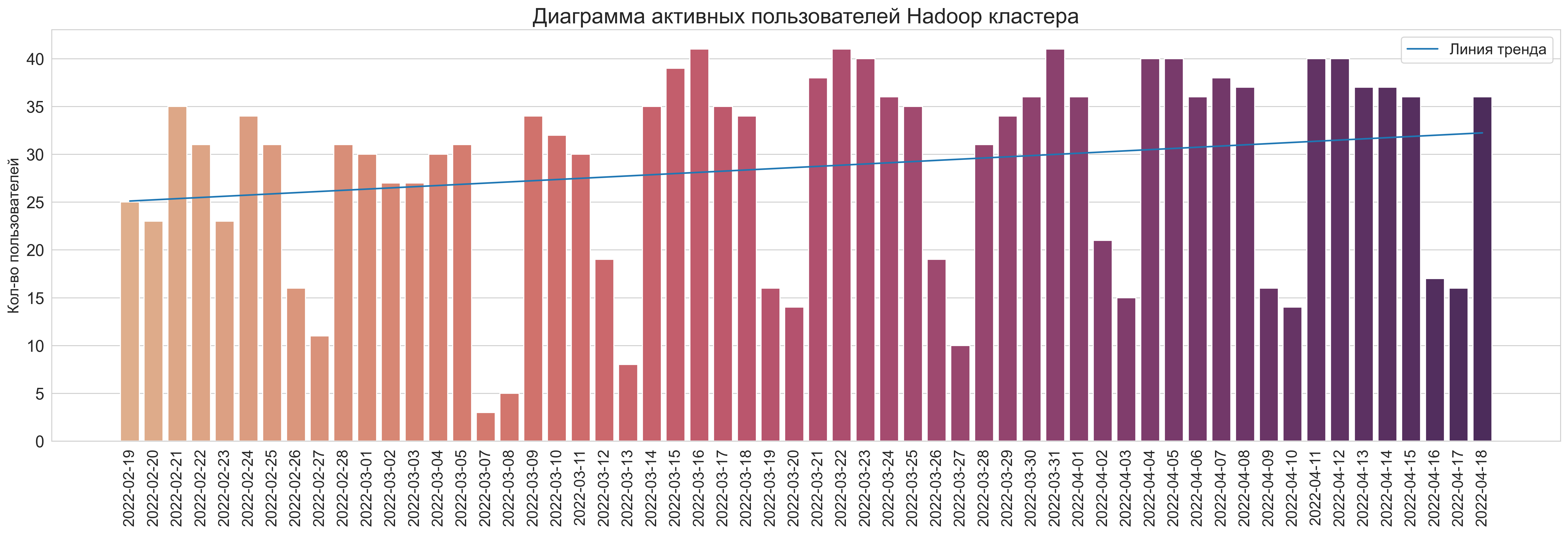
Кол-во уникальных пользователей по месяцам:
- Февраль:
49 - Март:
59 - Апрель (данные по 2022-04-18):
55
Всего пользователей за период: 69
Утилизация в дневное время (9:00 - 19:00)
Красной линией отмечена верхняя планка доступных ресурсов RAM/CPU в очереди.
with t_prepare as
(
select
*, row_number() over(
partition by app_id, run_number, dt order by parse_dt asc
) as row_n
from v_cluster
),
t_result as
(
select
count(*) as cnt
, sum(cpu) as cpu
, sum(memory)/1024 as memory
, run_number
, dt
from t_prepare
where
cast(substr(parse_dt, 12, 2) as int) between 9 and 19
and row_n = 1
group by dt, run_number
)
select avg(cnt) as cnt, avg(cpu) as cpu, avg(memory) as memory, dt
from t_result group by dt
RAM:
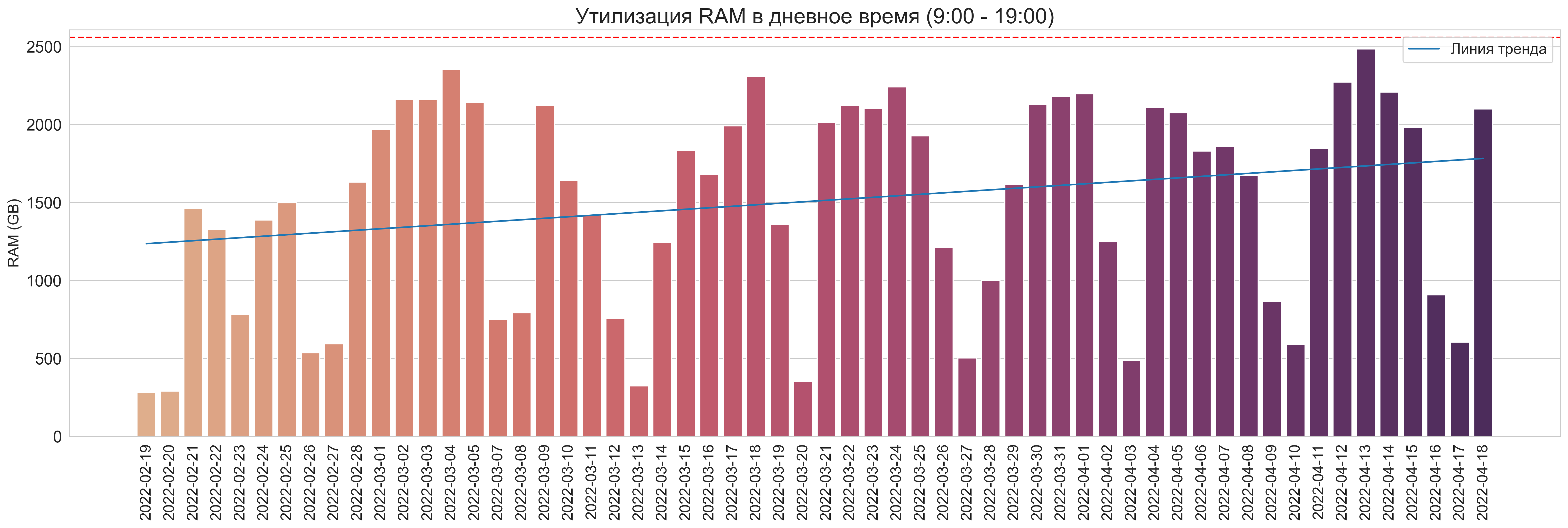
CPU:
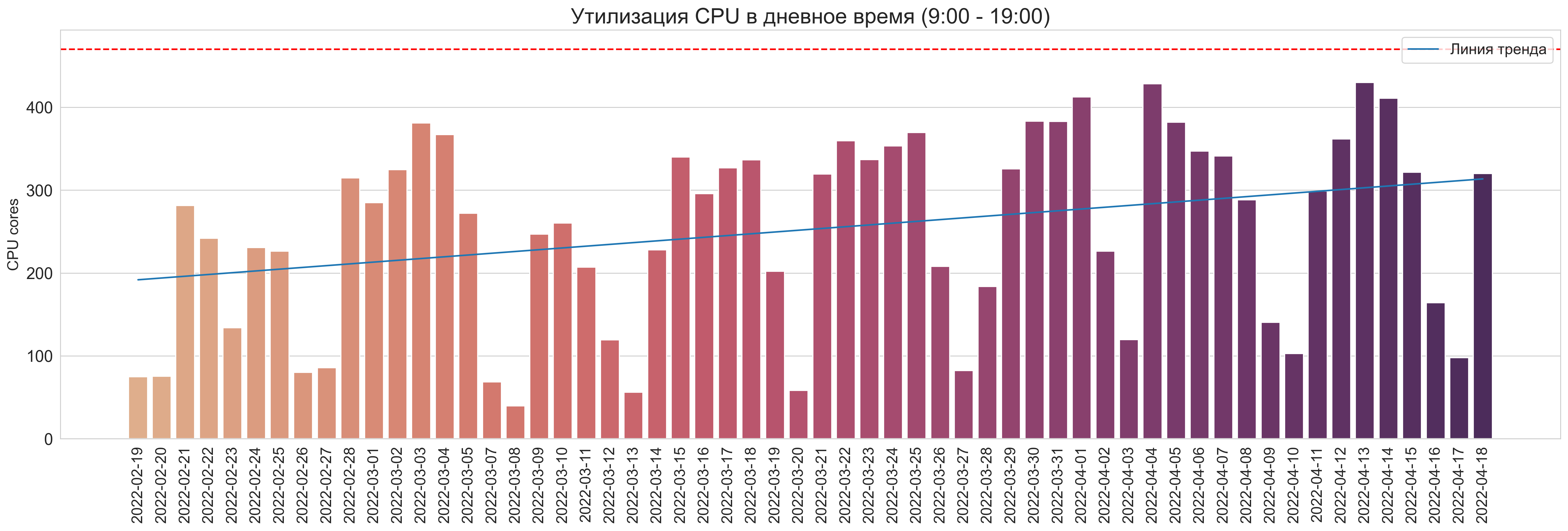
Утилизация в ночное время (00:00 - 08:00 & 20:00 - 24:00)
with t_prepare as
(
select
*, row_number() over(
partition by app_id, run_number, dt order by parse_dt asc
) as row_n
from v_cluster
),
t_result as
(
select
count(*) as cnt
, sum(cpu) as cpu
, sum(memory)/1024 as memory
, run_number
, dt
from t_prepare
where
cast(substr(parse_dt, 12, 2) as int) not between 8 and 20
and row_n = 1
group by dt, run_number
)
select avg(cnt) as cnt, avg(cpu) as cpu, avg(memory) as memory, dt
from t_result group by dt
RAM:
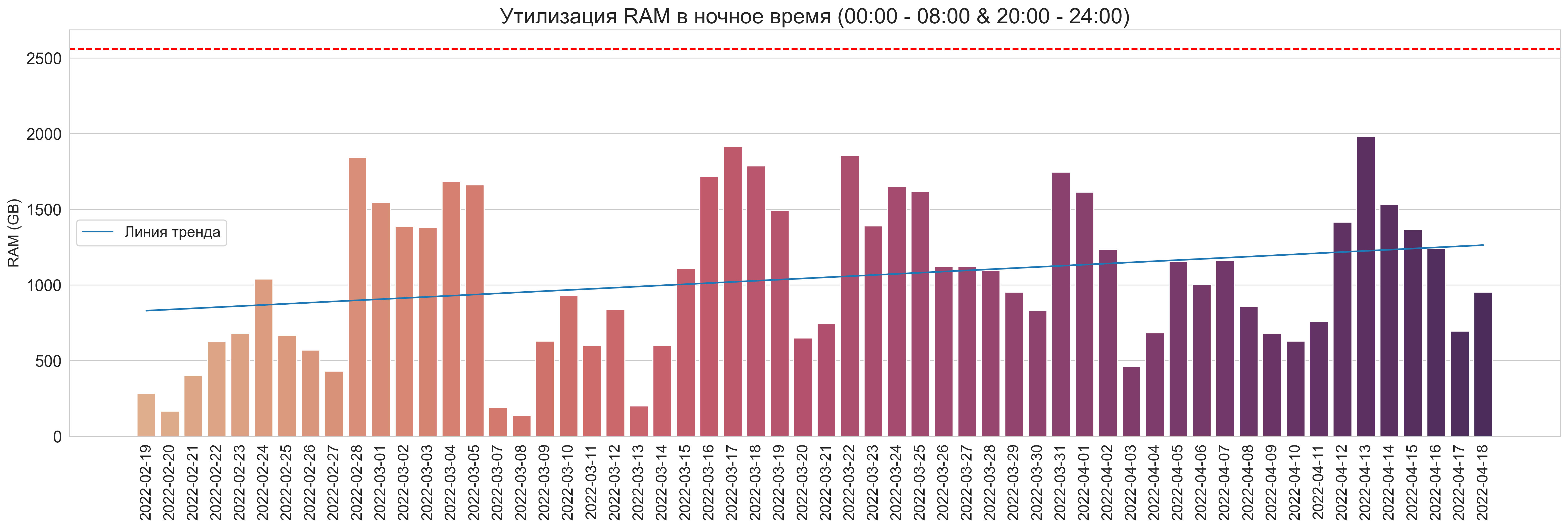
CPU:
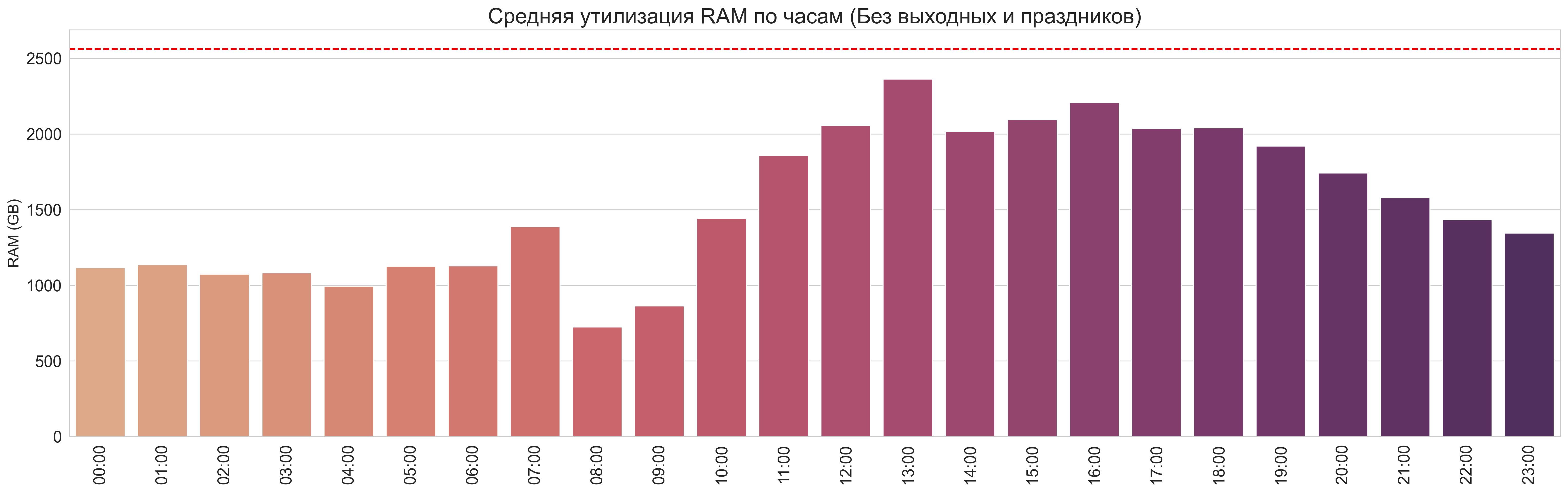
Средняя утилизация по часам
with t_prepare as (
select
*, cast(substr(parse_dt, 12, 2) as int) as n_hour
, row_number() over(
partition by app_id, run_number, dt order by parse_dt asc
) as row_n
from v_cluster
),
t_result as (
select
sum(cpu) as cpu
, sum(memory)/1024 as memory
, n_hour, dt
from t_prepare
where row_n = 1
group by n_hour, dt order by n_hour asc, dt desc
)
select round(avg(cpu)) as cpu, avg(memory) as memory, n_hour
from t_result group by n_hour order by n_hour asc
RAM:
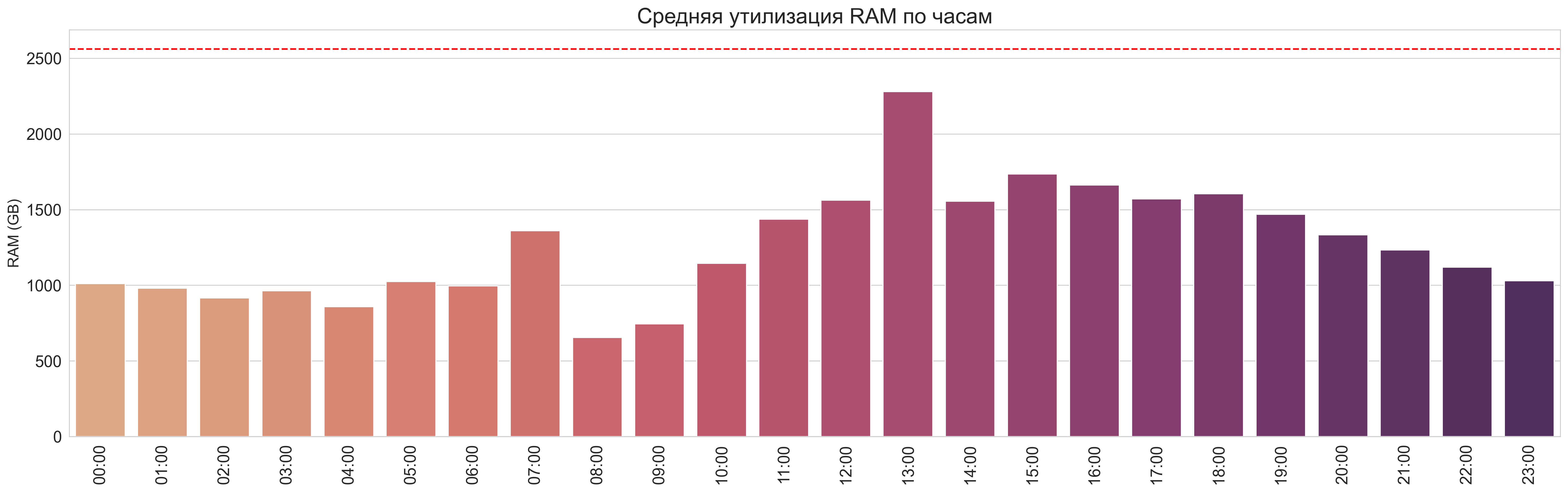
RAM (Без выходных):
CPU:
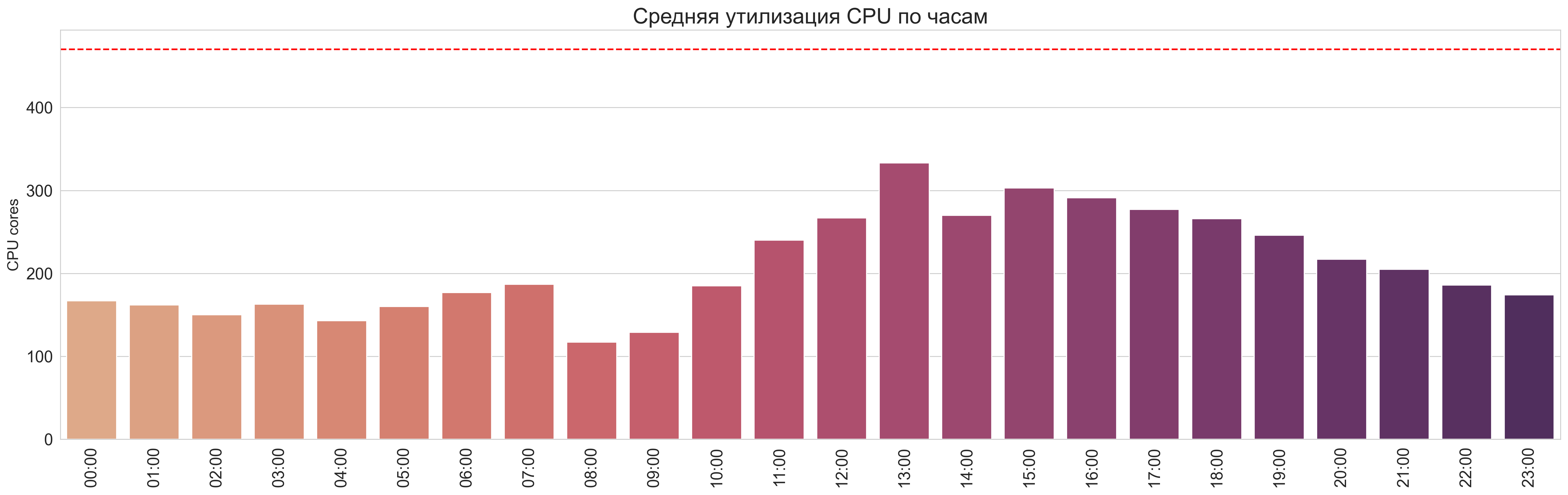
CPU (Без выходных):
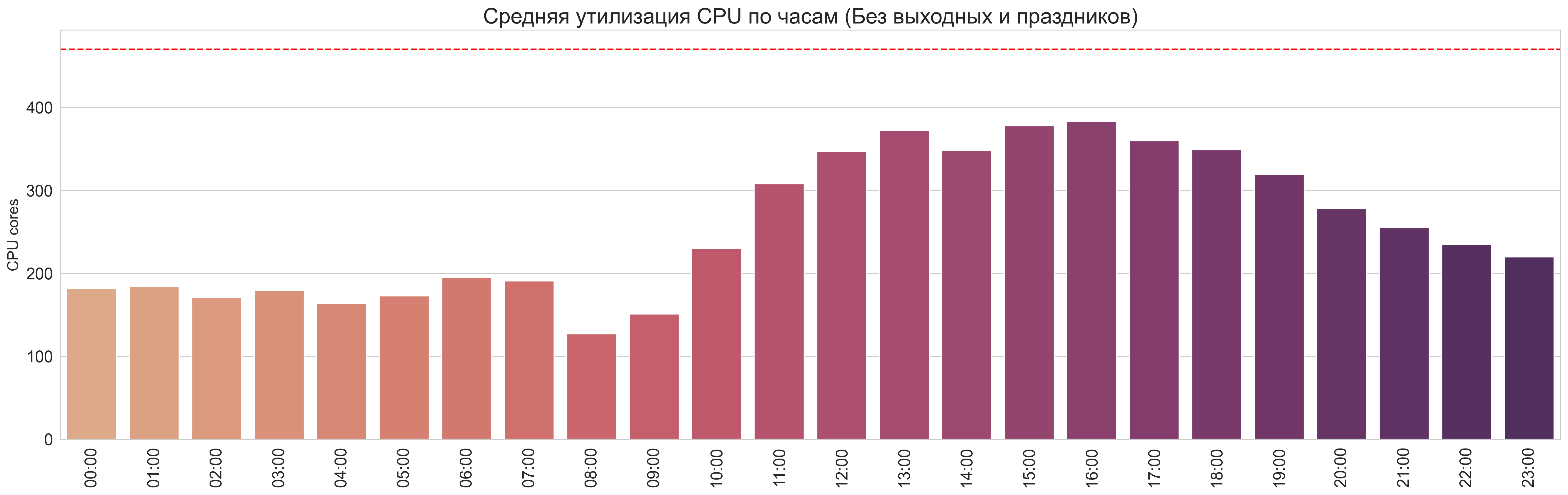
Средняя утилизация RAM+CPU на одном графике в процентном соотношении от максимальных ресурсов.
with t_prepare as (
select
*, cast(substr(parse_dt, 12, 2) as int) as n_hour
, row_number() over(
partition by app_id, run_number, dt order by parse_dt asc
) as row_n
from v_cluster
),
t_prepare_sum as (
select
sum(cpu) as cpu
, sum(memory)/1024 as memory
, n_hour, dt
from t_prepare where row_n = 1
group by n_hour, dt
),
t_result as (
select
round(avg(cpu)) as cpu
, avg(memory) as memory
, n_hour
from t_prepare_sum group by n_hour
)
select 'CPU' as type, cpu/470*100 as util_value, n_hour from t_result
union all
select 'RAM' as type, memory/2560*100 as util_value, n_hour from t_result
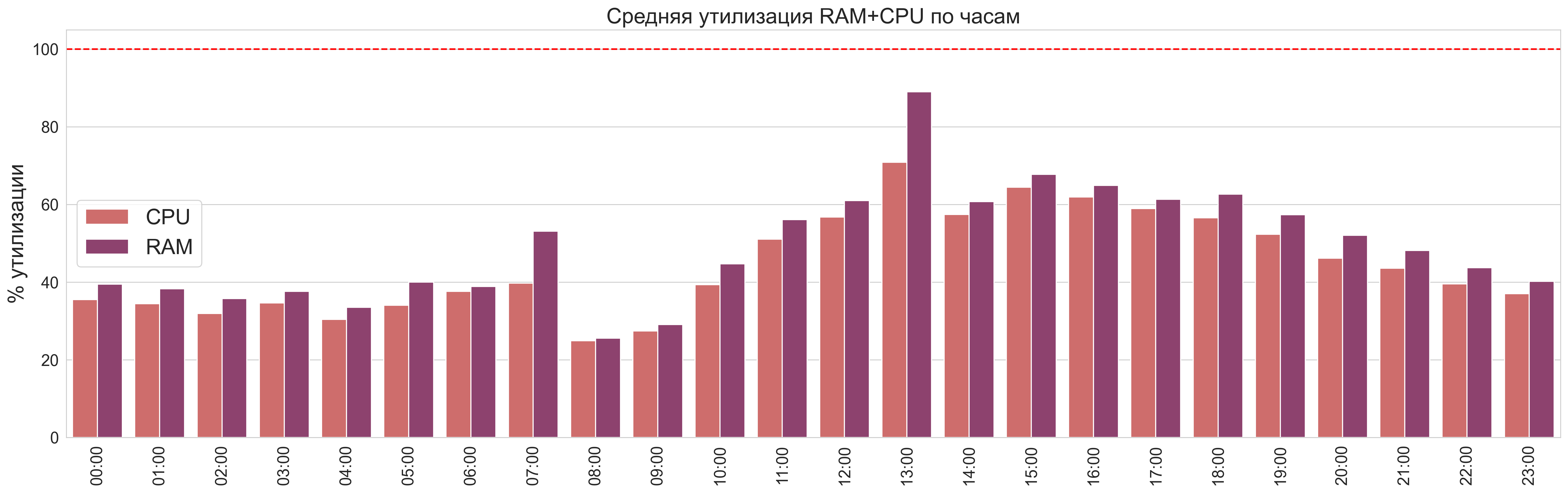
График только с рабочими днями:
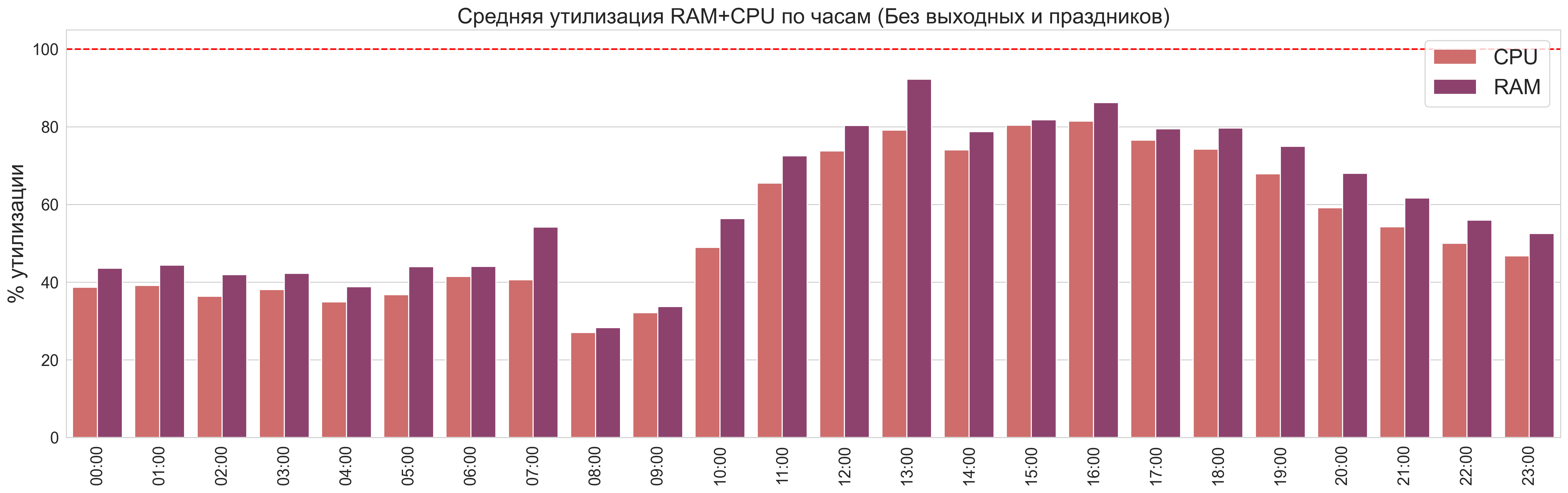
Из диаграммы видно, что ресурсы процессора недоутилизированы
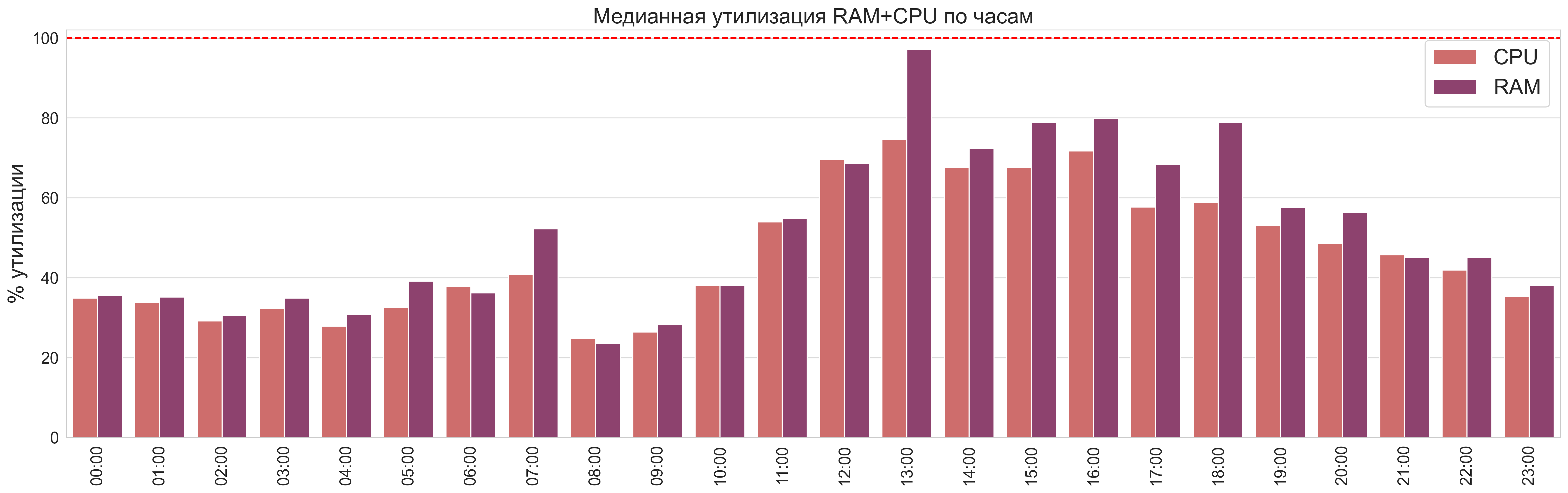
Аналогичный график для медианы.
Общая утилизация в % только в “рабочие” часы
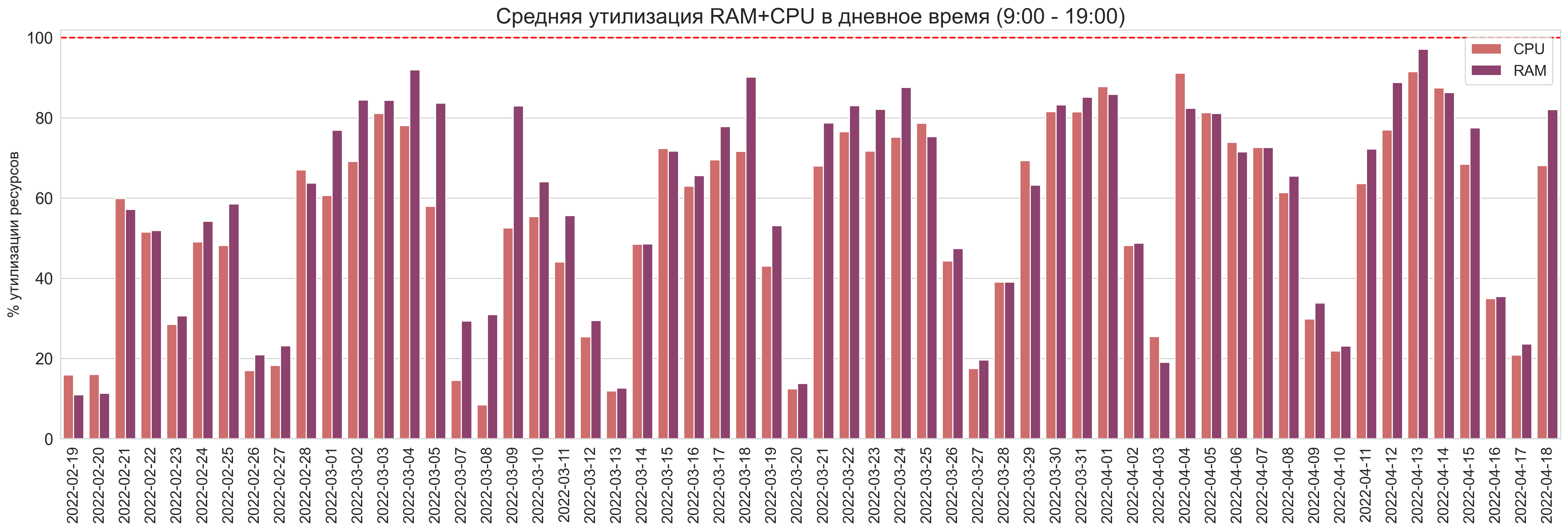
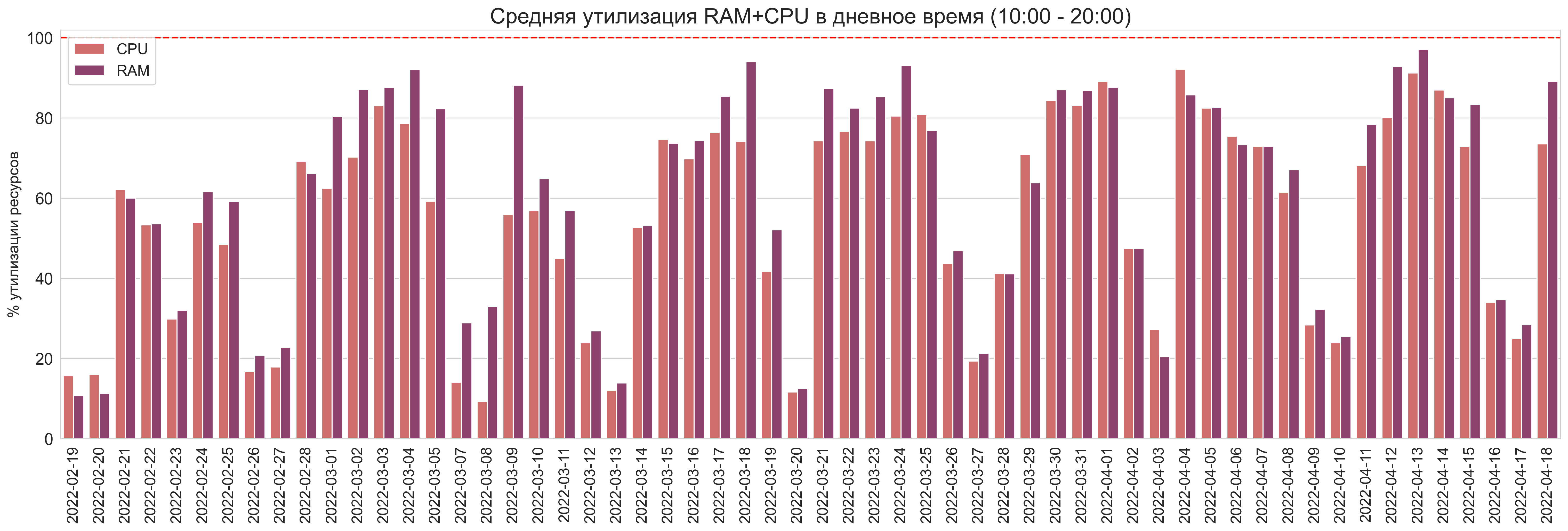
Немного сдвинем “рабочий день” до 10:00 - 20:00
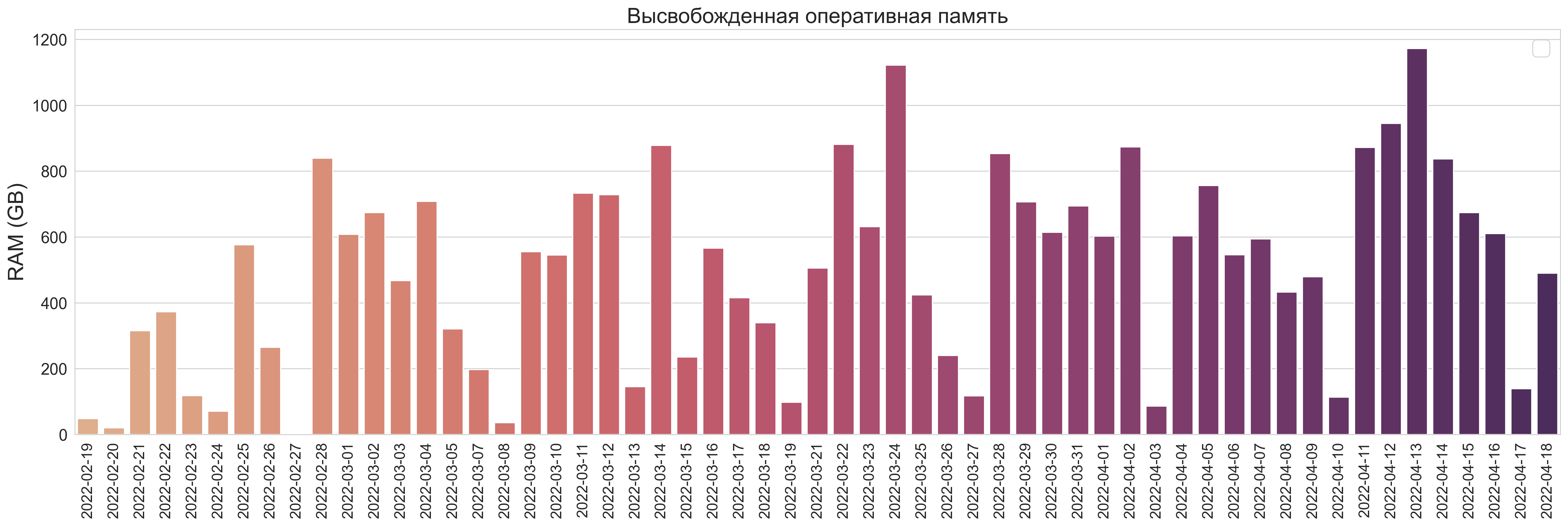
Результат высвобожденных ресурсов
select
dt
, sum(cpu) as cpu
, sum(memory)/1024 as ram
from v_cluster
where kill_reason <> '-'
group by dt
RAM:
CPU:
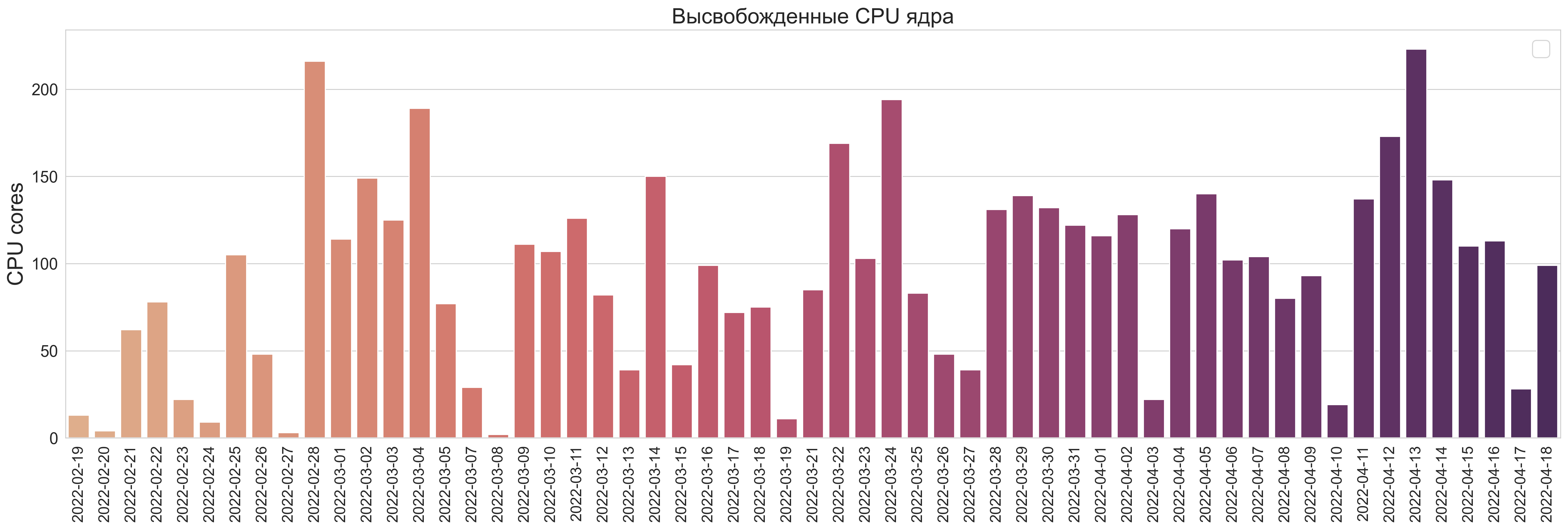
Ежедневно в очереди освобождается ~400-500 GB оперативной памяти и сопоставимое кол-во CPU ядер. Бывают и дни, в которые объемы неиспользуемой памяти достигают 800+ GB, что примерно 1/3 от всей yarn-очереди.
Если вам интересны подобные рассуждения, подписывайтесь на мой канал artydev & Co.