Загрузка и хранение дампов в Yandex S3

Регистрация в Yandex Cloud
Регистрируемся в https://console.yandex.cloud/
Создаем платежный аккаунт и получаем 2 стартовых гранта на 4000 рублей
Нажимаем Поиск, вводим Object Storage, далее Создать бакет.
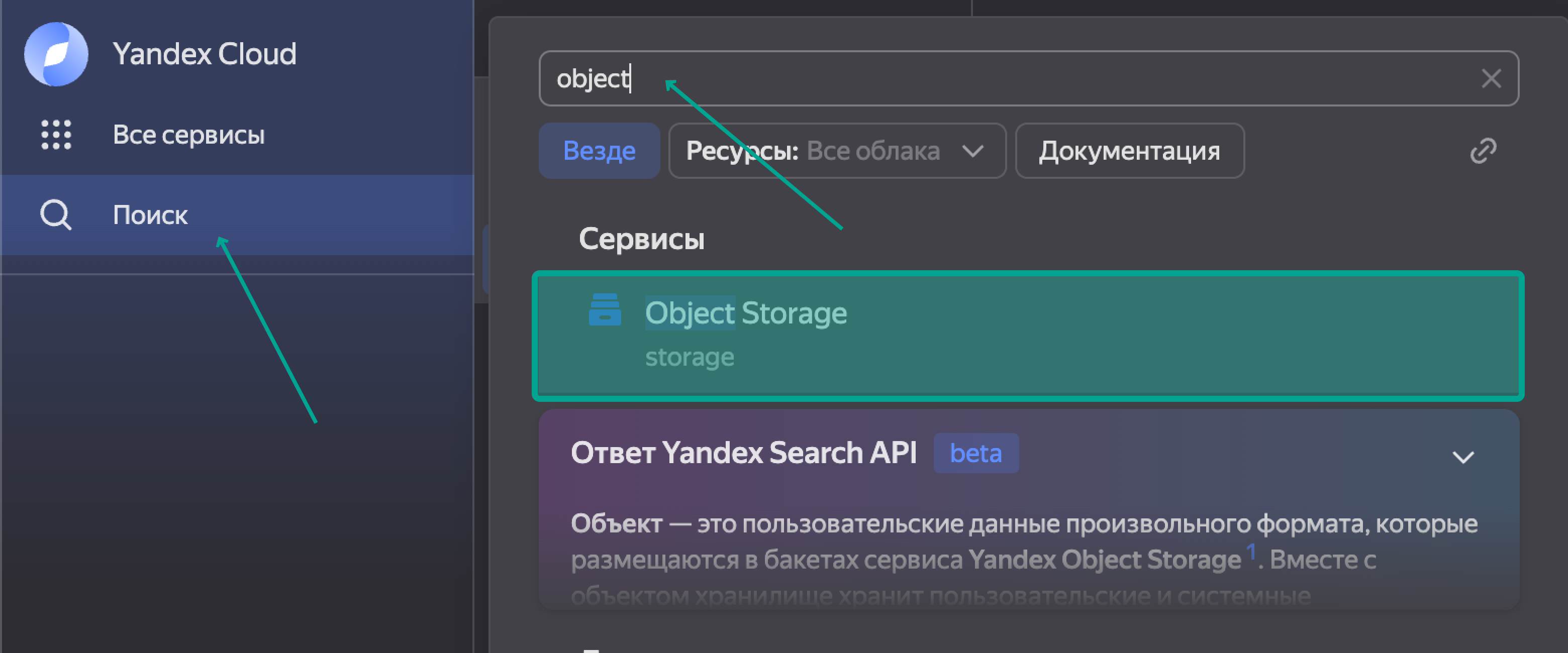
Прописываем название бакета, его максимальный размер и класс хранилища, почитать про разницу и тарификацию можно тут. В качестве примера я создаю бакет размером до 100 гигабайт и холодным классом хранилища.
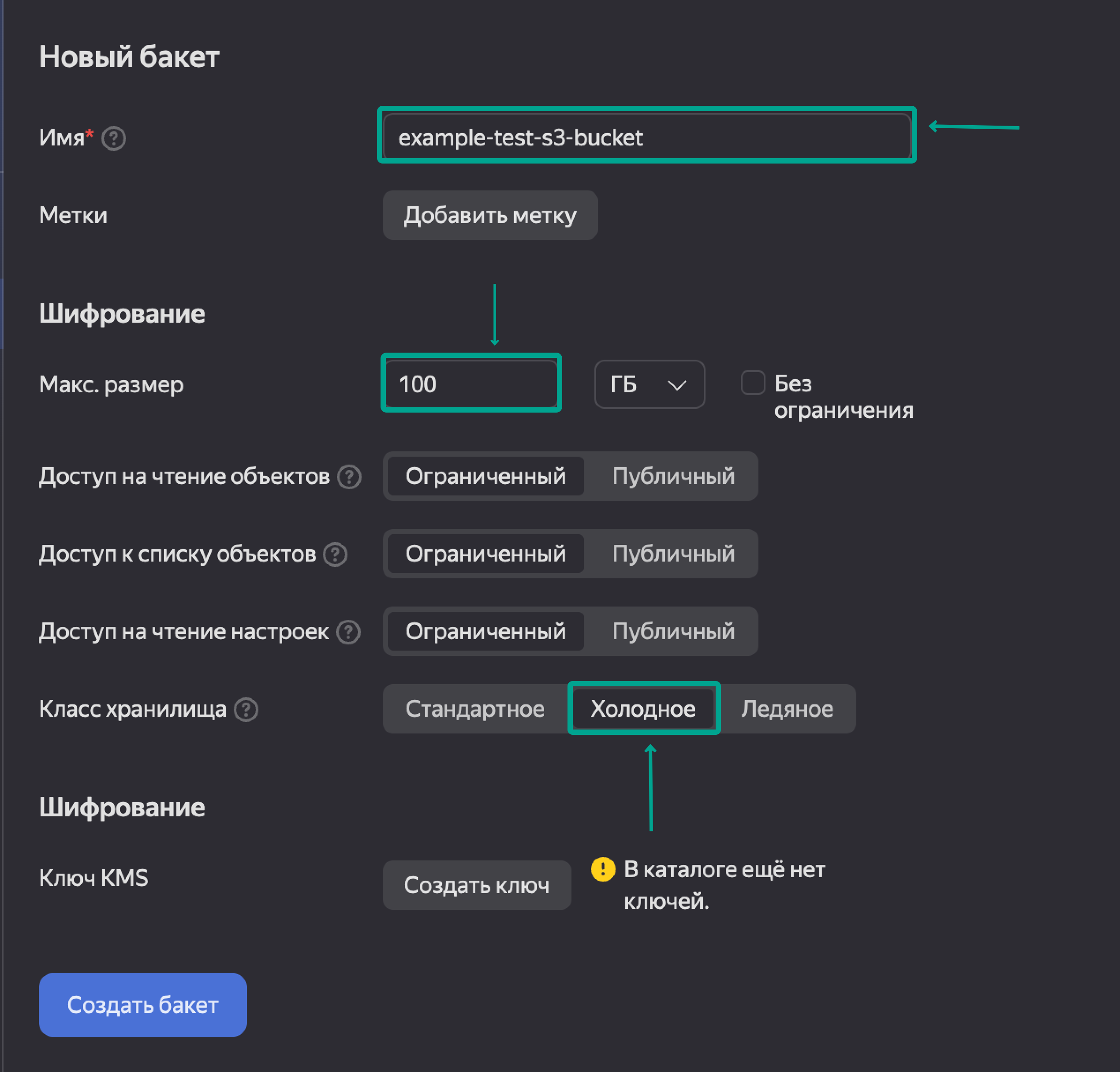
Далее нам необходимо создать сервисную запись: возвращаемся к поиску и вводим Identity and Access Managament, далее Создать сервисный аккаунт.
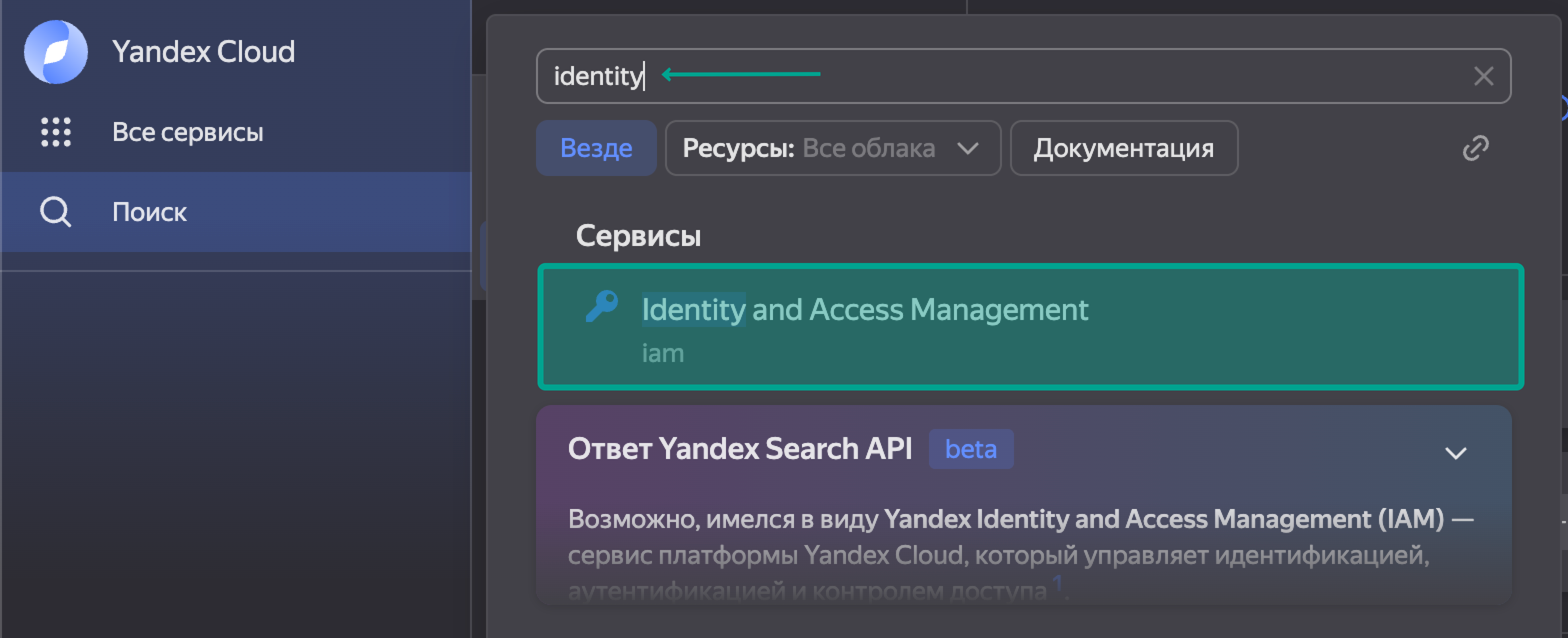
Вводим имя, описание и выбираем роли. Так как нас интересует работа с хранищем, то выбираем: stogare.viewer, storage.editor, storage.uploader.
После создания аккаунта нажимаем Создать новый ключ, выбирем Создать статический ключ доступа.
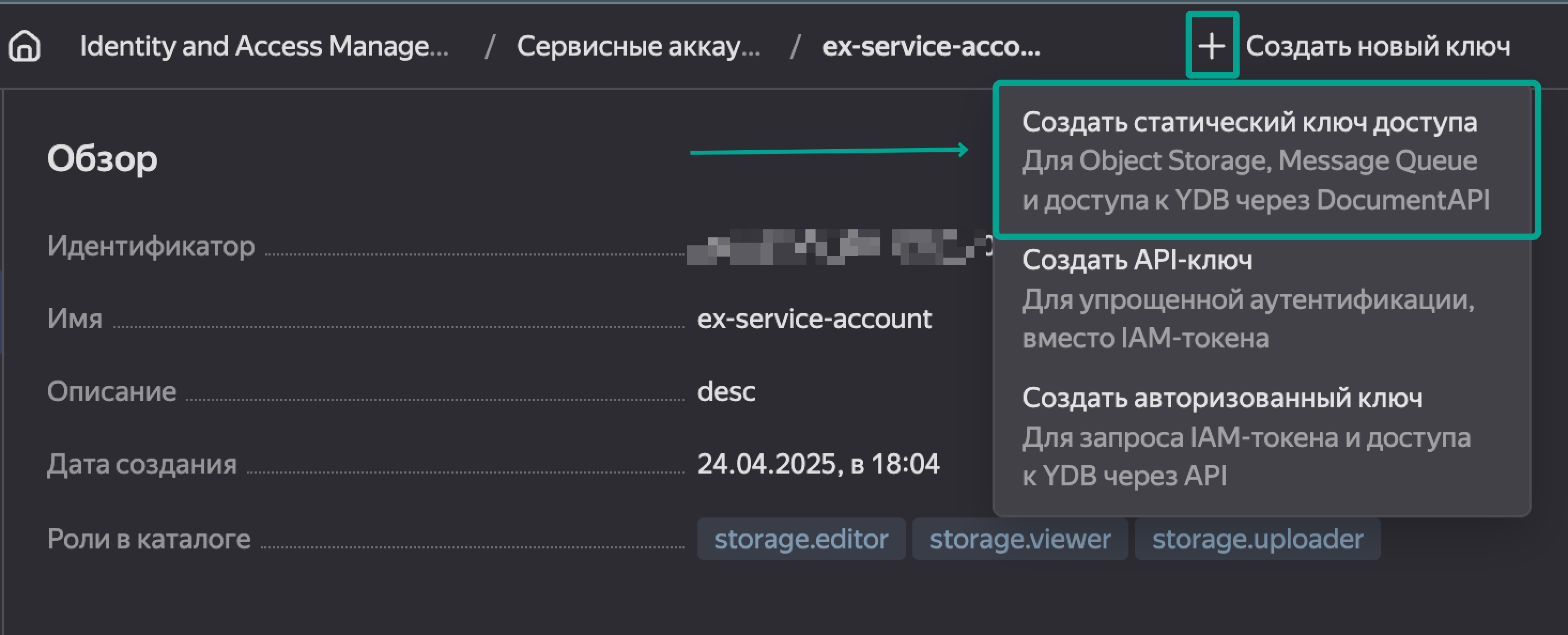
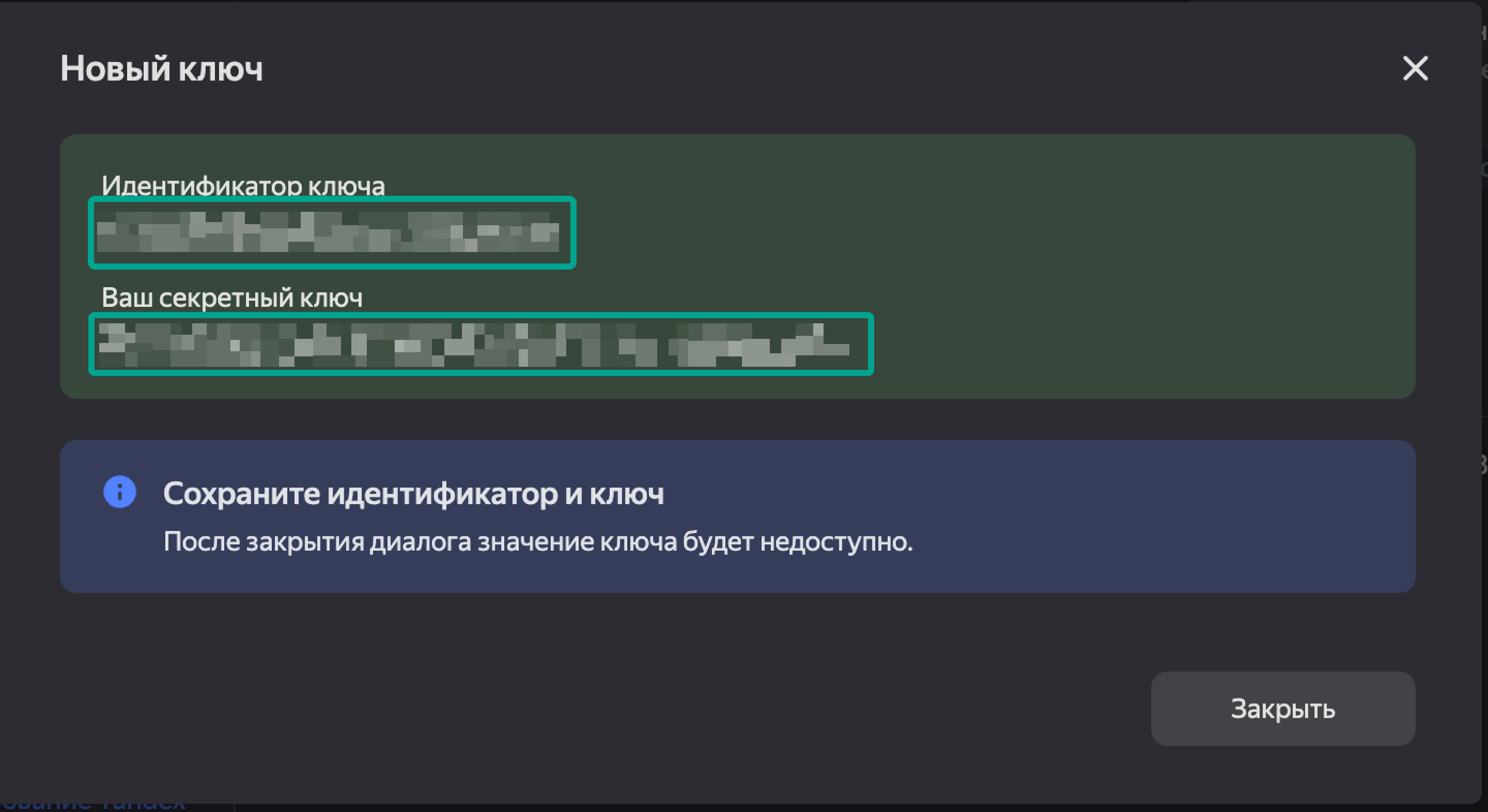
Обязательно сохраняем Идентификатор ключа и сам секретный ключ.
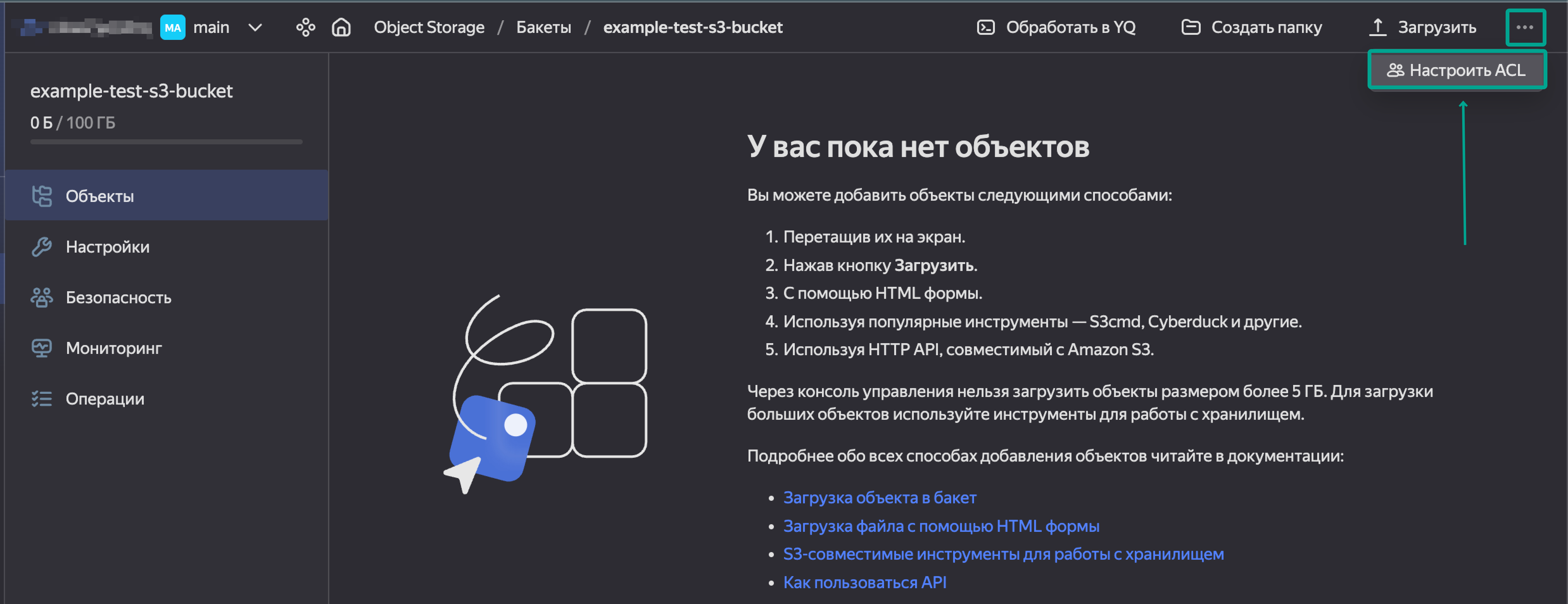
После создания возвращаемся в наш бакет и нажимаем Настроить ACL.
Добавляем сюда наш сервисный аккаунт и правами READ и WRITE. Нажимаем Добавить и Сохранить.
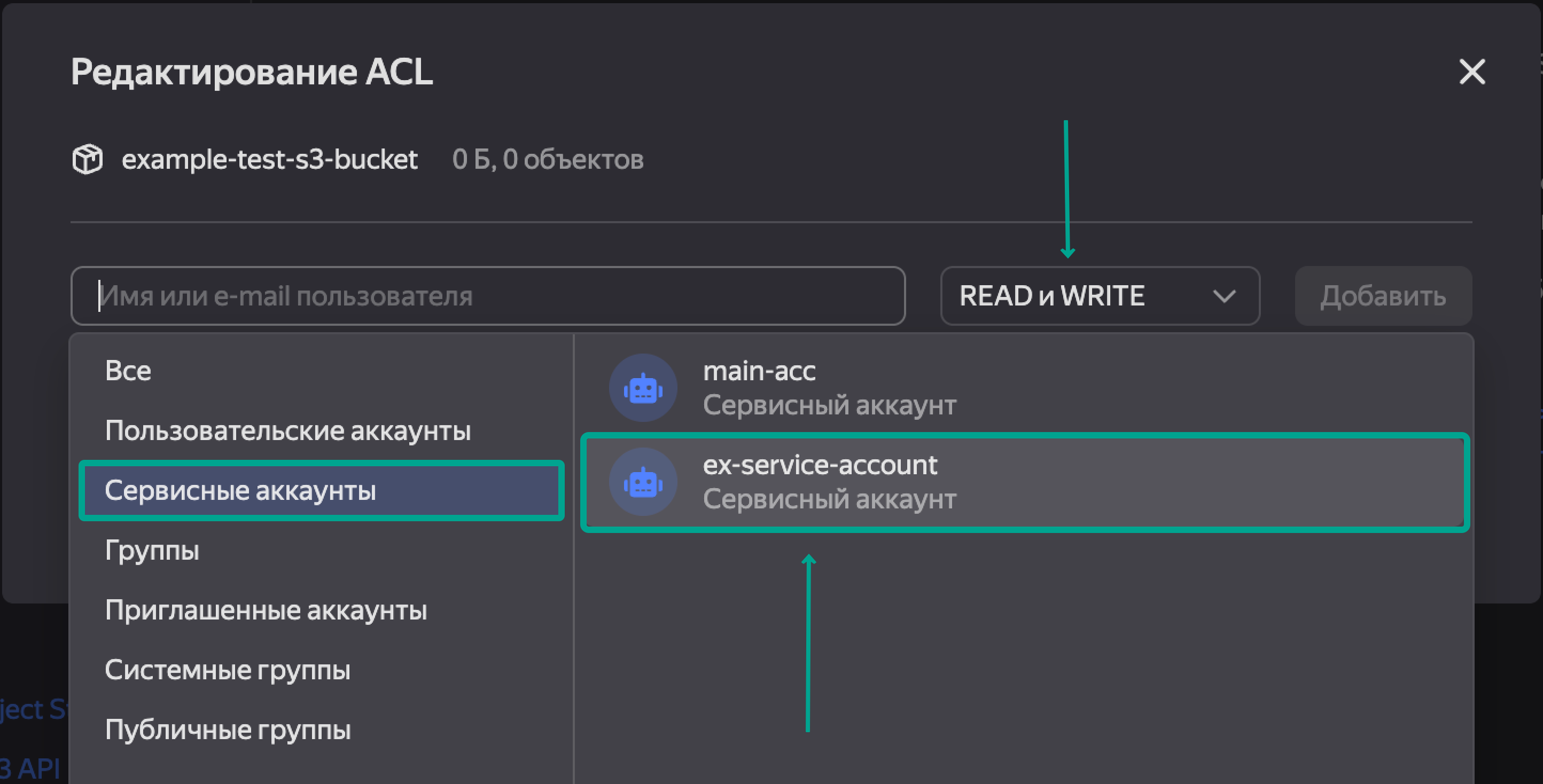
На данном этапе создан бакет, к нему привязан сервисный аккаунт, который может просматривать и загружать объекты в созданное облачное хранилище.
Автоматизация
В качестве примера будем рассматривать бэкапирование PostgreSQL в s3 бакет.
Создаем в домашней дирекории 2 файла и директорию .aws/credentials, файл pgpass необходим для того, чтобы команда снятия дампа не запрашивала пароль.
cd $HOME ;\
touch ~/.pgpass ;\
chmod 600 ~/.pgpass ;\
mkdir -p ~/.aws ;\
touch ~/.aws/credentials
Формат файла .pgpass
localhost:5432:database_name:username:password
Формат файла .aws/credentials
[default]
aws_access_key_id = <>
aws_secret_access_key = <>
Снимаем дамп с помощью pg_dump, сжимаем с помощью gzip и шифруем с помощью openssl.
<your ssl decrypt password> - меняем на свой пароль.
pg_dump database_name \
-U user \
-h localhost \
-v \
| gzip -c --best \
| openssl enc \
-aes-256-cbc \
-salt \
-pbkdf2 \
-iter 100000 \
-out <output file> \
-pass pass:<your ssl decrypt password>
Для расшифровки файла используем команду
openssl enc -d \
-aes-256-cbc \
-pbkdf2 \
-iter 100000 \
-in pg_dump_2025-04-24.sql.gz.enc \
-out pg_dump_2025-04-24.sql.gz \
-pass pass:<your ssl decrypt password>
Для распаковки файла используем команду
gzip -f -k -d pg_dump_2025-04-24.sql.gz > pg_dump_2025-04-24.sql
Готовый python код
Для работы с s3 нам понадобится библиотека boto3, ниже прикладываю упрощенный вариант скрипта загрузки файла в бакет.
import boto3
S3_BUCKET = "bucket name"
DUMP_FILE_NAME = "pg_dump_2025-04-24.sql.gz.enc"
def get_s3_instance():
session = boto3.session.Session()
return session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
def upload_dump_to_s3(dump_file: str):
get_s3_instance().upload_file(
Filename=dump_file,
Bucket=S3_BUCKET,
Key=dump_file
)
if __name__ == "__main__":
get_s3_instance().upload_dump_to_s3(DUMP_FILE_NAME)
Большое спасибо всем за внимание! Если вам интересны подобные рассуждения - подписывайтесь на мой канал artydev & Co.